How I ended up listening to the same song for 10 hours nonstop on August 20th, 2024
As 2024 comes to a close, Spotify has once again released its iconic Wrapped. One detail stood out to me: the day I listened to the same song for 10 hours straight—August 20, 2024.
That date immediately brought back memories. The weekend before (August 16–18) had been chaotic, marked by a major service outage. For nearly two days, we were scrambling to identify a persistent bug while operating at reduced capacity.
As I reflected, the pieces began to fall into place. It all traced back to January 2024. Looking back now, it’s almost funny to think about how it all unfolded—especially as I write this down. 🤣

Prequel
At the start of the year, we finished migrating to our new ledger system. This system made it easier to manage transactions and track the movement of “money” in our system. We faced some problems during the migration but solved them.
This was a big milestone. It was one of the largest migrations we had ever done. Everyone was happy, especially me. I led the project, and it was the hardest one I’ve done in my career so far. I’m proud of it because I helped build it from the ground up. We also completed the migration without losing money and without interrupting the service. Now that the system is stable, we can focus on an old problem: balance synchronization.
Balances were out of sync for many reasons. The most important one for this story was missing transactions. These transactions existed on our partner’s side but were not in our SQL database.
The issue was clear. It came down to how we implemented the Unit of Work.
Unit of Work (UoW) is a design pattern used in software development, especially in systems that interact with databases. It helps to manage transactions efficiently and ensures consistency by treating a series of operations as a single logical unit
begin;
select account;
perform I/O operation;
update account;
commit/rollback;
When an error occurs during a database operation, everything is rolled back.
This means we lose transactions in cases like network issues. However, these transactions still exist on our partner’s side. I’m simplifying it here to make it easy to understand.
A consequence of this issue is that balances are not always accurate. When this error happens, clients see incorrect balances on their end. It’s a strange and frustrating experience for anyone affected.
We are using the CQRS pattern. A quick solution to this issue was to introduce a command that synchronizes balances every time new transactions come in. This solution was implemented quickly and mitigated the issue for now. However, we identified that fixing this problem properly requires migrating some legacy code. Based on our infrastructure team’s calendar, we decided to postpone this migration for now.
I had an idea to fix the missing transactions issue: save the transaction before performing I/O calls that might fail. It was a simple fix. I wrote the code, tested it thoroughly, and everything worked. So, I deployed it. By then, it was already February.
We have a recurring job that runs daily to create a large number of transactions. The day after my fix, while this job was running, everything went wrong. The mobile app became unusable. Support teams reported that their tools had stopped working. Clients began complaining about the slowness of our service.
We investigated, and guess what? Our database was overwhelmed by locks. I couldn’t believe it. I hadn’t introduced any locks in my code!
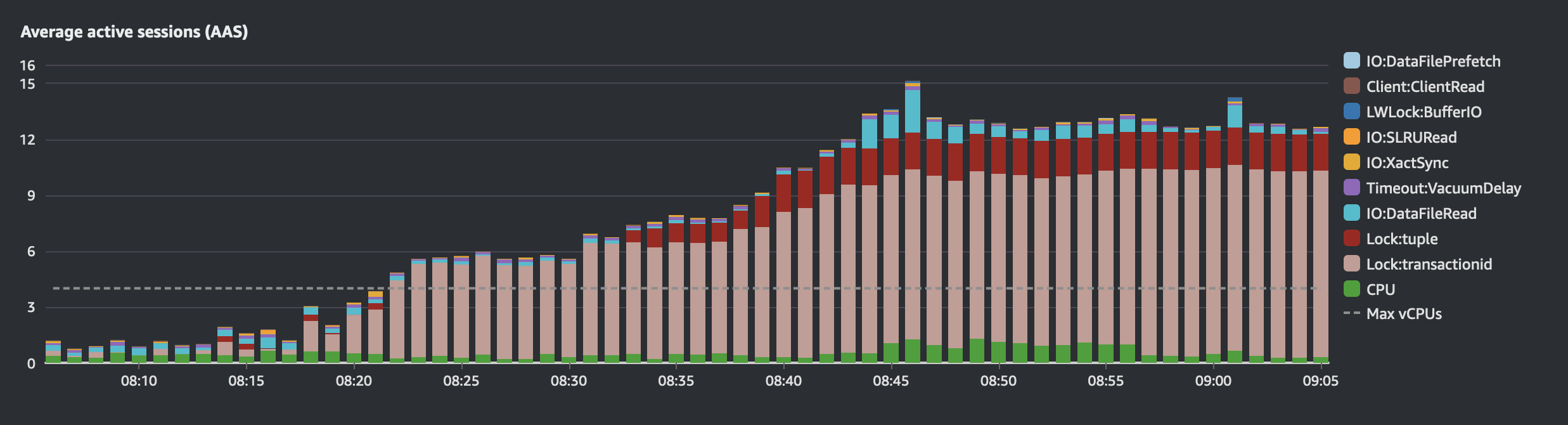
I know now, that for every query on a RDBMS there is a lock even if it is not explicit.
We rolled back my changes and conducted a postmortem. During the postmortem, my manager asked me to figure out why my fix had caused this issue.
At that time, I couldn’t understand what went wrong based on the knowledge I had. I don’t like not having answers, so I kept the problem in mind. Whenever I found some free time, I tried to reproduce the issue to understand it better.
My darkest weekend in 2024
After the February incident, I was involved in fewer issues and focused on achieving our quarterly objectives and system improvements. By mid-August, things took a turn.
Everything started with a new version of our mobile application. We released it on Tuesday, August 13th. By Thursday, clients began complaining about some features not working as expected. After investigating, we didn’t find anything unusual except for a small increase in traffic. Clients seemed to be using the app more after the release, which wasn’t alarming at the time.
By Friday, the complaints grew louder. Around 2 PM, the support engineering team tagged me in an issue: clients couldn’t perform transfers. I started investigating immediately. After 45 minutes, I couldn’t find the root cause, so I called for backup.
The team joined in, and by 3 PM, everything went downhill—a complete blackout. Transfers and deposits became impossible. Complaints poured in from clients and colleagues alike.
We noticed a sudden traffic spike, so we scaled up to double the maximum instances. A strange error in our RabbitMQ instance coincided with the incident; we resolved it. We also found and fixed some SQL queries that weren’t performing as expected.
We’re using the CQRS pattern on the affected microservices, and by Friday night, we still didn’t know the root cause. What we did know was that commands were impacted, not queries. We worked on it until 2 AM GMT, adding logs to understand what was happening.
During the night, things stabilized as traffic decreased. By 7 AM, I was back online, and top management demanded, “Let’s fix this by 9 AM.”
We began a fresh investigation. After adding more logs, we finally discovered the problem: connecting to the database was taking over 60 seconds. Mobile app requests were timing out but still being processed by the backend.
The issue wasn’t with the mobile app itself but with an endpoint for balance synchronization. This was the same endpoint we had added in the first quarter to keep balances in sync. The logic included an automatic retry if synchronization failed.
Here’s what was happening:
- Microservice A calls microservice B for balance synchronization (synchronously).
- Microservice A holds a connection to the DB.
- Microservice B also gets a DB connection and makes an HTTP call to our partners for the balance.
This process worked fine under normal traffic. However, the mobile release caused the app to send many unnecessary requests, even when users simply opened the app.
Combined, this led to a flood of DB connections. These connections held longer, and since our connection pool isn’t unlimited, requests were delayed, causing the blackout.
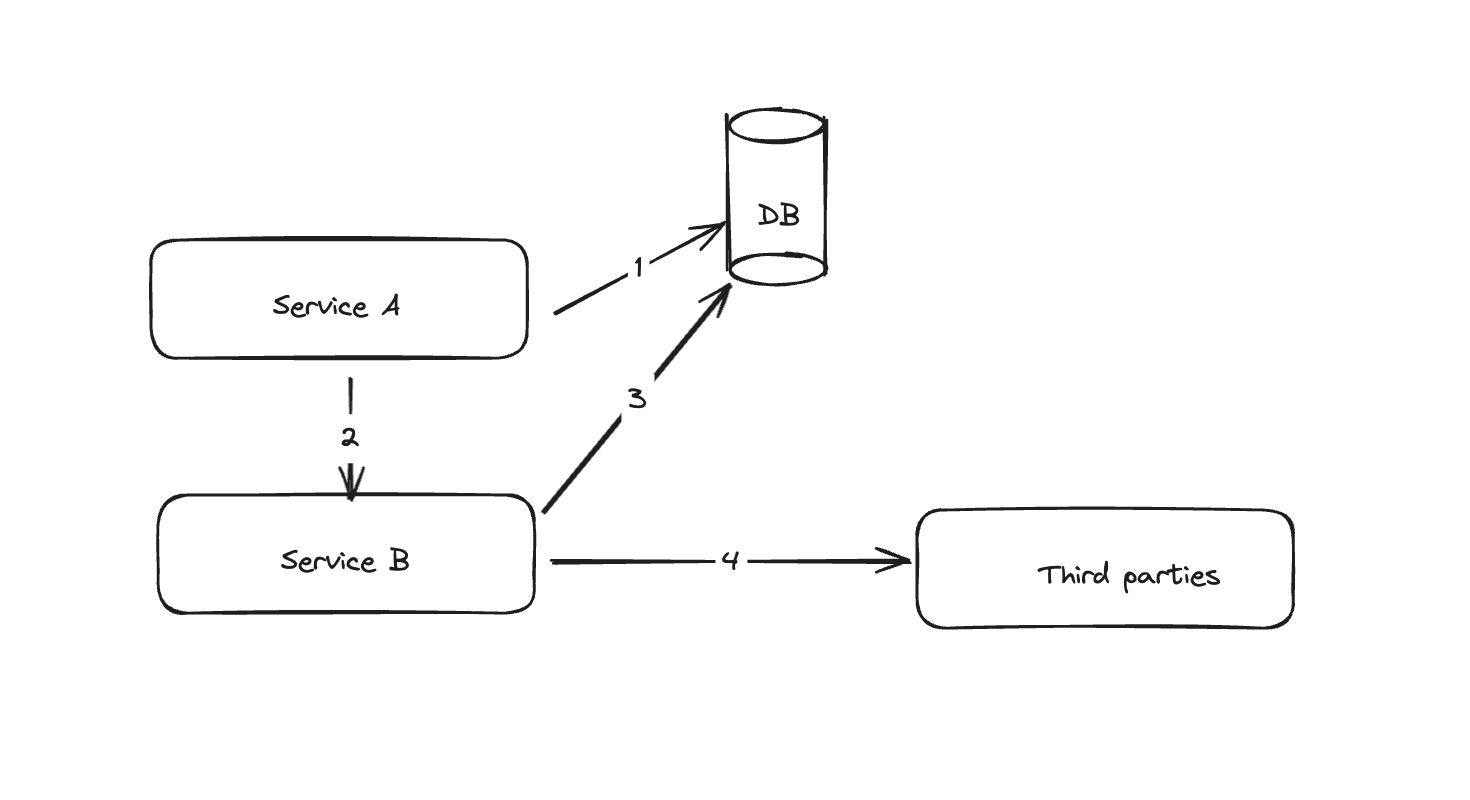
I began by removing the retry process to avoid an infinite loop of retries. This gave the database some breathing room, and we were able to free up available connections.
Next, we set a timeout on the connections, which started improving the situation. Another fix involved rewriting parts of the code to avoid blocking I/O while holding connections to the database.
These fixes were pushed around 10:30 PM on Saturday. We activated all services and monitored them closely until Monday.
August 20th, 2024
After we managed to get everything back up, I went to take a bath, still in shock. All of this happened because of the choices I made a few months ago. I couldn’t shake off the weight of it, so I began to listen to a single song: You Say Run by Yuki Hayashi.
On Monday, the goal was to reproduce the issue locally and start refactoring, focusing on normalizing how we interact with the database and managing blocking I/O calls. I was able to quickly reproduce the problem using load-testing tools.
Tuesday was all about finding a way to standardize our solution—how could we implement it efficiently with minimal effort? I worked on this with a colleague, and once again, I turned on my song for concentration. It played on a nonstop loop as we worked to develop a solution our manager would validate. Yes, that day, I listened to that song to help me focus and keep pushing forward, despite the mess I had created.
Lessons learned
What works for 100 calls won’t necessarily work for 1M calls.
Avoid blocking I/O between a transaction block on RDBMS.
Keep transaction blocks (at the database level) as short as possible to prevent microservices sharing the same DB from stepping on each other.
The database is the most sensitive part of the architecture. If an app messes with it, it can impact all systems that depend on it.
You can’t grow without making mistakes, but that doesn’t mean they should become a habit. Don’t make avoidable mistakes.
There’s “always” a lock somewhere when making a SQL query in an RDBMS.
I now fully understand what happened in the February incident. It was the same issue as this one, but inside the same app. Multiple DB connections were trying to manipulate the same rows.
Investing in observability tools is essential as you scale. If we had proper observability tools in place, we wouldn’t have spent over 24 hours before realizing the issue was related to database connection delays.
Conclusions
We were not prepared for this kind of situation, but we faced it head-on, and it showed us that we have the ability to scale and improve our code quality. During this incident, we were receiving more than double the usual traffic.
By improving our code quality, we gained a better understanding of what was happening, allowing us to support the increased load until the next mobile release. We’re now investing in observability tools to be better prepared for challenging days like these.
Additionally, I fixed the issue we faced in February. Transactions are now always saved before reaching our partners, and the database is handling the load from our recurring jobs with ease.
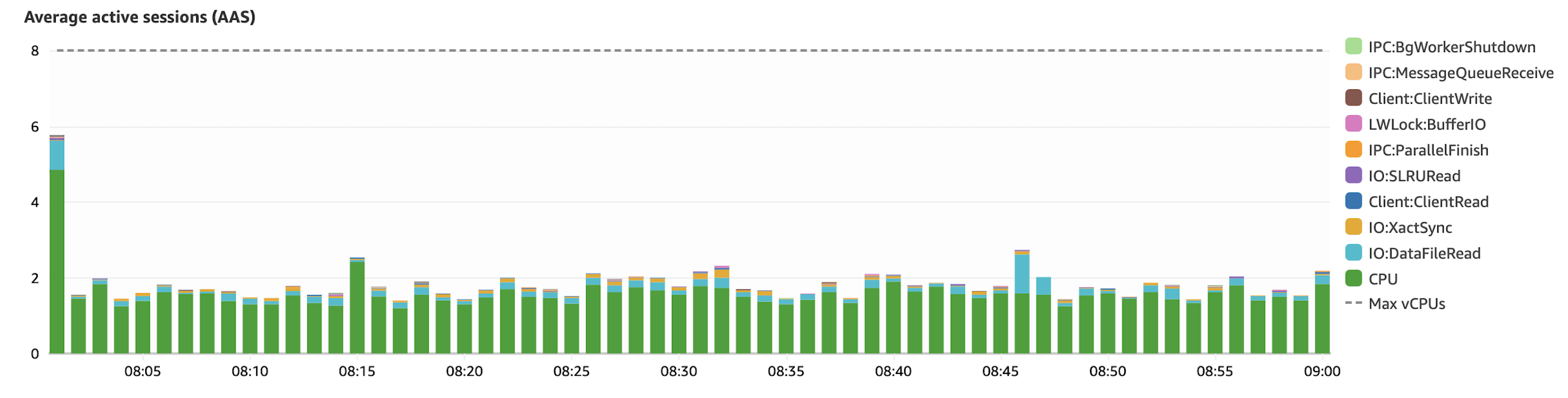
I’m embracing this interesting journey full of learnings as a software engineer.
Thanks for reading 😅.